Build your own Ubuntu AMI
TL;DR Scripts are available here: https://gist.github.com/matrey/66d697ef540f0da8933a341524ea9fd7
The steps in this article are run from an EC2 instance in the same region you want your AMI to be registered into. This builder VM should have the same architecture & OS as the image you intend to build. You can use the official Ubuntu AMI the first time, then use your own Ubuntu AMI for subsequent builds.
Note that the following focuses on building an Ubuntu bionic (18.04 LTS) AMI, as it has been my work horse for the past 2 years, and is still supported for another couple of years.
But if you are starting fresh, you should probably aim at focal (20.04 LTS).
Leverage Ubuntu Cloud Images
Rather than attempting to build an image from scratch, we will start with a ready made image from https://cloud-images.ubuntu.com
Given a codename (e.g. bionic or focal) we need to identify the most recent release available.
Ubuntu publishes release data in simple streams format. You can read more about it on https://github.com/smoser/talk-simplestreams/blob/master/Notes.txt
The following can be used to find the most recent bionic build:
$ sudo apt install simplestreams
$ sstream-query --no-verify --json --max=1 https://cloud-images.ubuntu.com/releases/streams/v1/com.ubuntu.cloud:released:download.sjson arch=amd64 release='bionic' ftype='disk1.img'
[
{
"aliases": "18.04,b,bionic",
"arch": "amd64",
"content_id": "com.ubuntu.cloud:released:download",
"datatype": "image-downloads",
"format": "products:1.0",
"ftype": "disk1.img",
"item_name": "disk1.img",
"item_url": "https://cloud-images.ubuntu.com/releases/server/releases/bionic/release-20201014/ubuntu-18.04-server-cloudimg-amd64.img",
"label": "release",
"license": "http://www.canonical.com/intellectual-property-policy",
"md5": "9aa011b2b79b1fe42a7c306555923b1b",
"os": "ubuntu",
"path": "server/releases/bionic/release-20201014/ubuntu-18.04-server-cloudimg-amd64.img",
"product_name": "com.ubuntu.cloud:server:18.04:amd64",
"pubname": "ubuntu-bionic-18.04-amd64-server-20201014",
"release": "bionic",
"release_codename": "Bionic Beaver",
"release_title": "18.04 LTS",
"sha256": "9fdd8fa3091b8a40ea3f571d3461b246fe4e75fbd329b217076f804c9dda06a3",
"size": "359923712",
"support_eol": "2023-04-26",
"supported": "True",
"updated": "Wed, 14 Oct 2020 18:20:34 +0000",
"version": "18.04",
"version_name": "20201014"
}
]However, it feels a bit overkill for what we need, and fortunately, there is also a "low tech" option available, relying on some text files at specific URLs.
There is a section at the bottom of https://help.ubuntu.com/community/UEC/Images explaining how these text files work:
Machine Consumable Ubuntu Cloud Guest images Availability Data
In order to provide information about what builds are available for download or running on ec2, a 'query' interface is exposed at http://cloud-images.ubuntu.com/query . This will allow users of the service to download images or find out the latest ec2 AMIs programmatically.
The data is laid out as follows:
There are 2 files in top level director 'daily.latest.txt' and 'released.latest.txt'. Each of these files contains tab delimited data, with 4 fields per record. daily.latest.txt has information about the daily builds, released.latest.tt about released builds:
<suite> <build_name> <label> <serial> hardy server release 20100128For each record in the top level files another set of files will exist:
<suite>/<build_name>/released-dl.current.txtdownloadable images data for the most recent released build- [...]
The downloadable image data files contain 7 tab delimited fields:
<suite> <build_name> <label> <serial> <arch> <download_path> <suggested_name> maverick server daily 20100826 i386 server/maverick/20100826/maverick-server-uec-i386.tar.gz ubuntu-maverick-daily-i386-server-20100826
We are interested in the "released" version, not the "daily" builds. So we just need to download https://cloud-images.ubuntu.com/query/bionic/server/released-dl.current.txt and grep for our architecture:
$ curl -Ss 'https://cloud-images.ubuntu.com/query/bionic/server/released-dl.current.txt' | grep amd64 | tr '\t' '\n'
bionic
server
release
20201014
amd64
server/releases/bionic/release-20201014/ubuntu-18.04-server-cloudimg-amd64.tar.gz
ubuntu-bionic-18.04-amd64-server-20201014Note that we could also directly take a blind shot and download from https://cloud-images.ubuntu.com/releases/bionic/release/, which always points to the latest release. But:
- knowing the build date helps validate the most recent image is newer than what we already have (2 to 3 weeks can elapse between 2 "released" images)
- we would need to rely on a hardcoded name fragment, e.g. "ubuntu-18.04-server-cloudimg-amd64" for
bionic
Convert the image
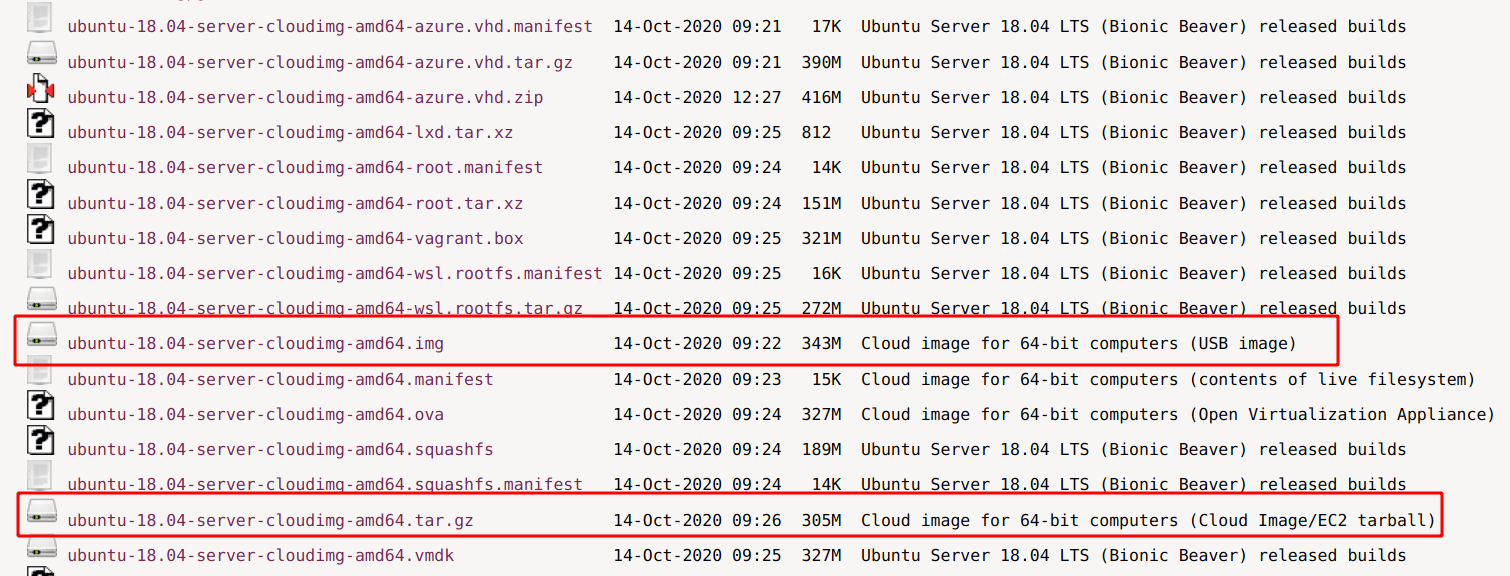
Column 6 of "released-dl.current.txt" provides us the "download_path", with a URI ending in ".tar.gz":
server/releases/bionic/release-20201014/ubuntu-18.04-server-cloudimg-amd64.tar.gzAccording to the directory listing, this is in a "Cloud Image/EC2 tarball" format.
However... I never got a booting instance this way, so instead we will go for the ".img" version, which un-helpfully reads "USB image", but is actually a qcow2 disk image.
First, we need to convert the qcow2 image into raw. Note that where qcow2 images are "sparse" (unused disk space doesn't count), raw images require the same amount of space as their size (i.e. several GB).
$ sudo apt-get install qemu-utils
$ qemu-img convert -O raw ubuntu-18.04-server-cloudimg-amd64.img ubuntu-18.04-server-cloudimg-amd64.rawThe raw image is ready to "burn" into an EBS volume. We will leverage the AWS CLI for the following steps.
Make the AMI
Here is a high-level overview of what we need to do:
- Create a new EBS volume
- Attach the new EBS to the current instance managing the build
- Use
ddto write the raw image to the volume - Detach the volume
- Request a snapshot of the volume and wait until it is completed
- Delete the volume
- Register the snapshot as an AMI
We will need to create an IAM policy that allows these actions through AWS APIs, without exposing the account too much. Granularity is not too great, and the way I found to lock down actions as much as possible relies on tags (on the builder instance and on the volume & snapshot).
- The builder VM should have a tag "WithRole=amibuilder"
- We will give the same tag to the temporary EBS volume we will write the image onto
While not as tightly locked down as I would have liked, restricting permissions this way still has the nice side-effect of preventing some mistakes (e.g. can't detach the wrong volume from a different instance)
Here is the IAM policy I ended up with:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:RegisterImage",
"ec2:DescribeVolumes",
"ec2:CreateSnapshot",
"ec2:DescribeSnapshots",
"ec2:CreateVolume"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ec2:DetachVolume",
"ec2:AttachVolume",
"ec2:DeleteVolume"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"ec2:ResourceTag/WithRole": "amibuilder"
}
}
},
{
"Effect": "Allow",
"Action": "ec2:CreateTags",
"Resource": "arn:aws:ec2:*:*:volume/*",
"Condition": {
"StringEquals": {
"ec2:CreateAction": "CreateVolume"
}
}
},
{
"Effect": "Allow",
"Action": "ec2:CreateTags",
"Resource": "arn:aws:ec2:*:*:snapshot/*",
"Condition": {
"StringEquals": {
"ec2:CreateAction": "CreateSnapshot"
}
}
}
]
}Subsequent steps rely on the AWS cli. Setup instructions are provided at: https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2-linux.html
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
rm -rf aws awscliv2.zip We want to create a volume just big enough for our raw image. So for that, we need to check the image size, and the trick is to use du --apparent-size (on some bionic raw image, du returned 1.1 GB whereas du --apparent-size returned a more proper 2.2 GB). And using --block-size=1G directly gives us a value rounded up to the next GB.
$ SIZE=$( du --block-size=1G --apparent-size "ubuntu-18.04-server-cloudimg-amd64.raw" | cut -f 1 )
$ aws ec2 create-volume --tag-specifications 'ResourceType=volume,Tags=[{Key=WithRole,Value=amibuilder},{Key=Name,Value="AMI building"}]' --availability-zone "ap-southeast-1" --size "$SIZE" --volume-type gp2 --output text --query 'VolumeId'Once the volume is created, we need to attach it to our builder instance. But it's not really obvious where it will end up: /dev/sd{x}? /dev/xvd{x}? /dev/nvme{x}n{y}?
We will use lsblk before attaching the volume, then after attaching it, and compare the two, to figure out where the new volume landed.
lsblk --json | jq --raw-output .blockdevices[].name | sort > "${TMPDIR}/volumes-before.txt"
cp "${TMPDIR}/volumes-before.txt" "${TMPDIR}/volumes-after.txt"
instance_id=$(curl -L -Ss http://169.254.169.254/latest/meta-data/instance-id)
aws ec2 attach-volume --device /dev/sdi --instance-id "$instance_id" --volume-id "$volumeid" --output text --query 'State'
while cmp "${TMPDIR}/volumes-before.txt" "${TMPDIR}/volumes-after.txt" >/dev/null 2>/dev/null; do
lsblk --json | jq --raw-output .blockdevices[].name | sort > "${TMPDIR}/volumes-after.txt"
sleep 3;
done
# If we are here, it means a new device appeared
NEWDEV=$( comm -13 "${TMPDIR}/volumes-before.txt" "${TMPDIR}/volumes-after.txt" | head -n1 )
dev=/dev/${NEWDEV}As an extra precaution, in the case of NVMe volumes, we can actually query the "sn" attribute and confirm it matches the ID returned by ec2 create-volume.
$ sudo apt-get install nvme-cli
$ nvme id-ctrl "/dev/${DEVICE_NAME}" --output-format=json | jq --raw-output .sn | sed -e 's/vol/vol-/'We then just dd the raw image onto the device
dd if="ubuntu-18.04-server-cloudimg-amd64.raw" of="$dev" bs=8MThen run the rest of the API calls to detach the volume and make a snapshot of it. Note that snapshots are fairly slow, it's not uncommon to have to wait several minutes, even for a tiny 4 GB volume. Once we have the snapshot, we can delete the volume.
# Detach the volume
aws ec2 detach-volume --volume-id "$volumeid" --output text --query 'State'
while aws ec2 describe-volumes --volume-id "$volumeid" --output text --query 'Volumes[*].State' | grep -v -q available; do
sleep 3;
done
# Create a snapshot of the volume
snapshotid=$(aws ec2 create-snapshot --tag-specifications 'ResourceType=snapshot,Tags=[{Key=Name,Value="For AMI"}]' --description "${LABEL}" --volume-id "$volumeid" --output text --query 'SnapshotId')
while aws ec2 describe-snapshots --snapshot-id "$snapshotid" --output text --query 'Snapshots[*].State' | grep -q pending; do
sleep 10;
done
# We can now delete the volume
aws ec2 delete-volume --volume-id "$volumeid" --output textFinally, we register the snapshot as an AMI.
If you want to have a nice logo in the AMI list, make sure to include "ubuntu" somewhere into the AMI name. Thanks https://www.turnkeylinux.org/comment/12501:
AWS automatically 'determine' the platform by parsing the image name. So, if Ubuntu is included in the image name, the platform will be Ubuntu. If Redhat is included in the name, the platform will be Redhat. It's just for show...
# Register the snapshot as a new AMI
block_device_mapping=$(cat <<EOF
[
{
"DeviceName": "/dev/sda1",
"Ebs": {
"DeleteOnTermination": false,
"SnapshotId": "$snapshotid",
"VolumeSize": $SIZE,
"VolumeType": "gp2"
}
}, {
"DeviceName": "/dev/sdb",
"VirtualName": "ephemeral0"
}
]
EOF
)
amiid=$(aws ec2 register-image --name "${LABEL}" --ena-support --description "${LABEL}" --architecture x86_64 --virtualization-type hvm --block-device-mapping "$block_device_mapping" --root-device-name "/dev/sda1" --output text --query 'ImageId')
echo "Published AMI ${amiid} in region ${AWS_DEFAULT_REGION}"That's it! You are now able to use your own AMI! Which is... pretty much identical to the official Ubuntu AMI. So what's the point?
Building our own AMIs actually allows us to customize them.
Customize the AMI
Once you have the raw image, you can actually attach it to a loop device, mount it, and edit it.
For that we will use losetup:
devloop=$( losetup -f ) # e.g. /dev/loop0
losetup -f -P "ubuntu-18.04-server-cloudimg-amd64.raw"
MOUNTPOINT=/mount/image
mkdir -p "$MOUNTPOINT"
mount "${devloop}p1" "$MOUNTPOINT"Next, in order to run our custom script in a chroot, we need to tweak the environment a bit:
# Allow network access from chroot environment
if [[ -e "$MOUNTPOINT/etc/resolv.conf" ]] || [[ -L "$MOUNTPOINT/etc/resolv.conf" ]]; then
mv $MOUNTPOINT/etc/resolv.conf $MOUNTPOINT/etc/resolv.conf.bak
fi
cat /etc/resolv.conf > $MOUNTPOINT/etc/resolv.conf
# Extra mounts
mount -t proc none $MOUNTPOINT/proc/
mount -t sysfs none $MOUNTPOINT/sys/
mount -o bind /dev $MOUNTPOINT/dev/
# prevent daemons from starting during apt-get
echo -e '#!/bin/sh\nexit 101' > $MOUNTPOINT/usr/sbin/policy-rc.d
chmod 755 $MOUNTPOINT/usr/sbin/policy-rc.dWe can now run our script under chroot:
cp "${CHROOT_SCRIPT}" $MOUNTPOINT/tmp/custom_user_script
chroot $MOUNTPOINT /tmp/custom_user_script
rm -f $MOUNTPOINT/tmp/custom_user_scriptThis is not very different from RUN lines in a Dockerfile. Here are for instance some commands I would use to setup Docker, Netdata (monitoring) and Fluentbit (logging) on the image:
# Add utilities
apt-get install --no-install-recommends -y apt-transport-https ca-certificates curl software-properties-common make zip unzip jq
# Install docker
curl -L -o /etc/apt/trusted.gpg.d/docker.asc 'https://download.docker.com/linux/ubuntu/gpg'
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
apt-get update
apt-get install -y docker-ce docker-ce-cli containerd.io
systemctl enable docker
# Install netdata
curl -L -o /etc/apt/trusted.gpg.d/netdata.asc https://packagecloud.io/netdata/netdata/gpgkey
add-apt-repository -s "deb https://packagecloud.io/netdata/netdata/ubuntu/ bionic main"
apt-get update
apt-get install -y netdata
# Install fluentbit
curl -L -o /etc/apt/trusted.gpg.d/fluentbit.asc http://packages.fluentbit.io/fluentbit.key
add-apt-repository "deb http://packages.fluentbit.io/ubuntu/bionic bionic main"
apt-get update
apt-get install -y td-agent-bitNote that some packages don't like being installed that way ; e.g. I wasn't able to preinstall Percona server, because it has a post-install script waiting forever on the service to start. YMMV.
Once we are done, we cleanup out tweaks:
# Unmount extra mountpoints
for PT in dev proc sys; do
umount "$MOUNTPOINT/$PT"
done
# Put resolv.conf symlink back in place
rm -f $MOUNTPOINT/etc/resolv.conf
if [[ -e "$MOUNTPOINT/etc/resolv.conf.bak" ]] || [[ -L "$MOUNTPOINT/etc/resolv.conf.bak" ]]; then
mv $MOUNTPOINT/etc/resolv.conf.bak $MOUNTPOINT/etc/resolv.conf
fi
# Clean up policy-rc.d
rm -f $MOUNTPOINT/usr/sbin/policy-rc.dComplete script
Visit https://gist.github.com/matrey/66d697ef540f0da8933a341524ea9fd7 to get ec2-create-ubuntu-ami.sh and ubuntu-bionic-extra.sh.
Sample usage:
sudo env AWS_SHARED_CREDENTIALS_FILE=/home/ubuntu/.aws-creds \
bash /home/ubuntu/ec2-create-ubuntu-ami.sh \
--codename bionic --keep-binaries --add-size 1G \
--run-script /home/ubuntu/ubuntu-bionic-extra.sh \
--label ubuntu-docker-host 2>&1 | tee log-docker-ami-2020-10-12.logWhy not... ?
Why not use the official AMI directly?
- Back in 2016 AWS China had no marketplace, you had to build your own AMI
- It allows customizing the instance, and contrary to
cloud-config, the instance is ready to use right after boot
Why not create an instance, configure it and make its snapshot into an AMI?
- From prior Windows sysadmin experience, I had to
sysprepthe master instance to reset the instance-specific SID - On Linux, it's not very clear what should be removed / cleaned up: bash history, SSH host keys, authorized_keys, but probably also some more arcane things like
/etc/machine-id,/var/lib/systemd/random-seed, etc. It's much better if they have never been there in the first place.
Why not use packer?
- Scratch your own itch? (:
- What we did is probably similar to Packer's Amazon
chrootbuilder: https://www.packer.io/docs/builders/amazon-chroot
References
- https://github.com/alestic/alestic-git/blob/master/bin/alestic-git-build-ami for the overall approach and ec2 commands
- https://github.com/kickstarter/build-ubuntu-ami/blob/master/data/user_data.sh.erb for the user script run in chroot
- https://blog.tinned-software.net/mount-raw-image-of-entire-disc/ for how to mount the raw image with losetup
